CS6675 Web Crawler
This post is the analysis for my first homework assignment of CS6675.
View the source code at My Github.
Overview
For this assignment, we were tasked to experiment and record metrics of various open source webcrawlers or search engines.
Web Crawler

For my webcrawler, I decided to make my own web crawler in Node on top of the npm package Crawler which makes pulling the HTML for a specific URL very easy. In addition, it contains a url queue that we can use to keep track of how many URLs are waiting to be scraped.
Design
My overall design for the crawler was to make my seed url https://www.cc.gatech.edu, and only crawled links that had hrefs that were relative to the url. This method ensured that the crawled links were derivatives of the seed url. I used a set of visited links to ensure duplicate links were not crawled, and just crawled with a Breadth First Search graph traversal.
I also used a NLP library “natural” to tokenize and stem the text found in the webpage to count the number of distinct keywords extracted.
While this design may work in the small instance of cc.gatech.edu, the BFS traversal would limit the depth of the visited sites at scale because there could be a potential for the links to keep linking to other sites and restring the crawler from reaching pages with more content than the surface-level pages.
Here is a screenshot of the logged output of the crawler at the beginning of the crawl. Note that the time is recorded in milliseconds.
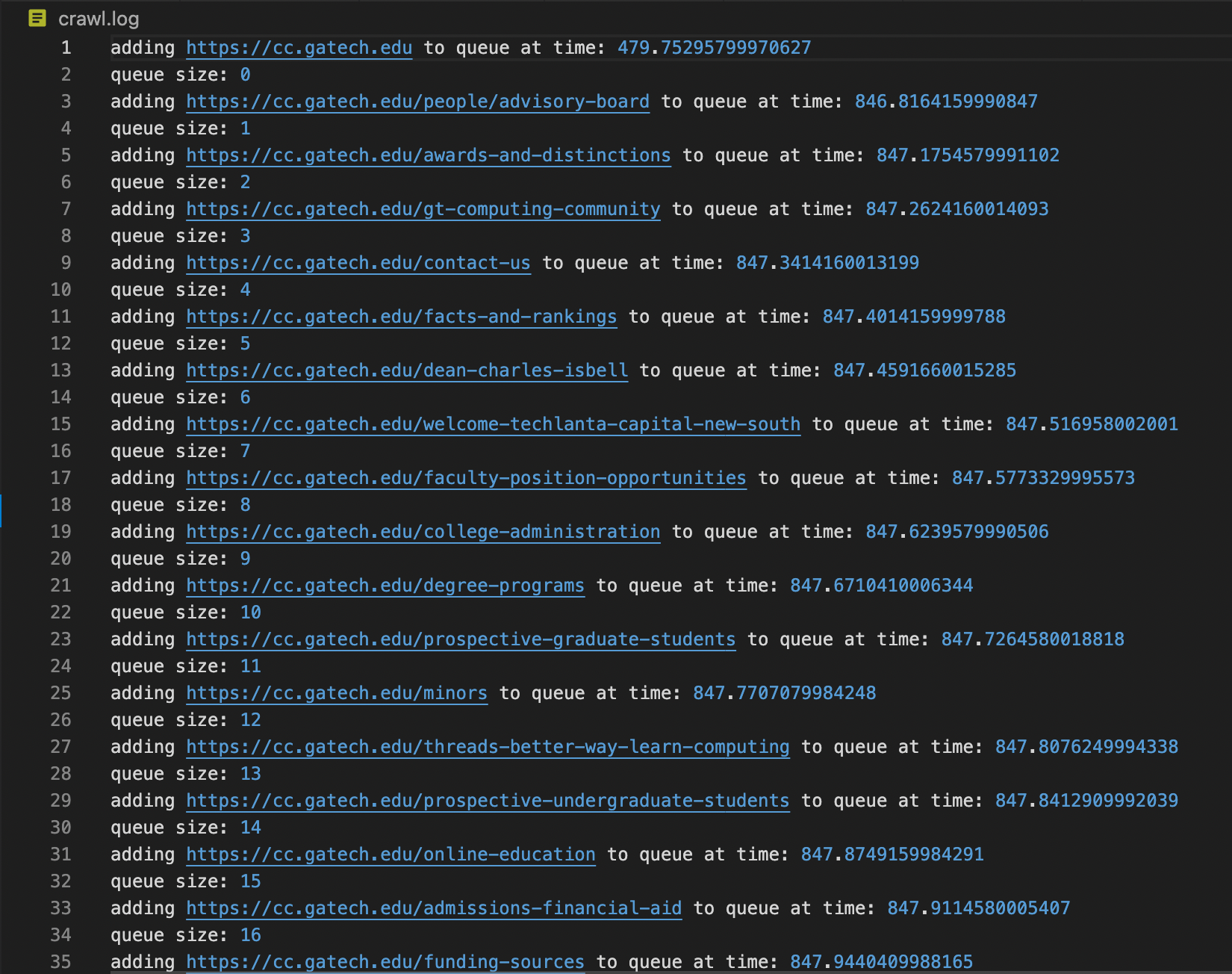
Web Archive

I stored my data in a MongoDB collection, where every webpage has the following fields:
- title: the title field of HTML
- content_stemmed: the stemmed keywords extracted from the body of HTML
- uri: the uri of the site
Example of cc.gatech.edu:

MongoDB Compass Visualization:
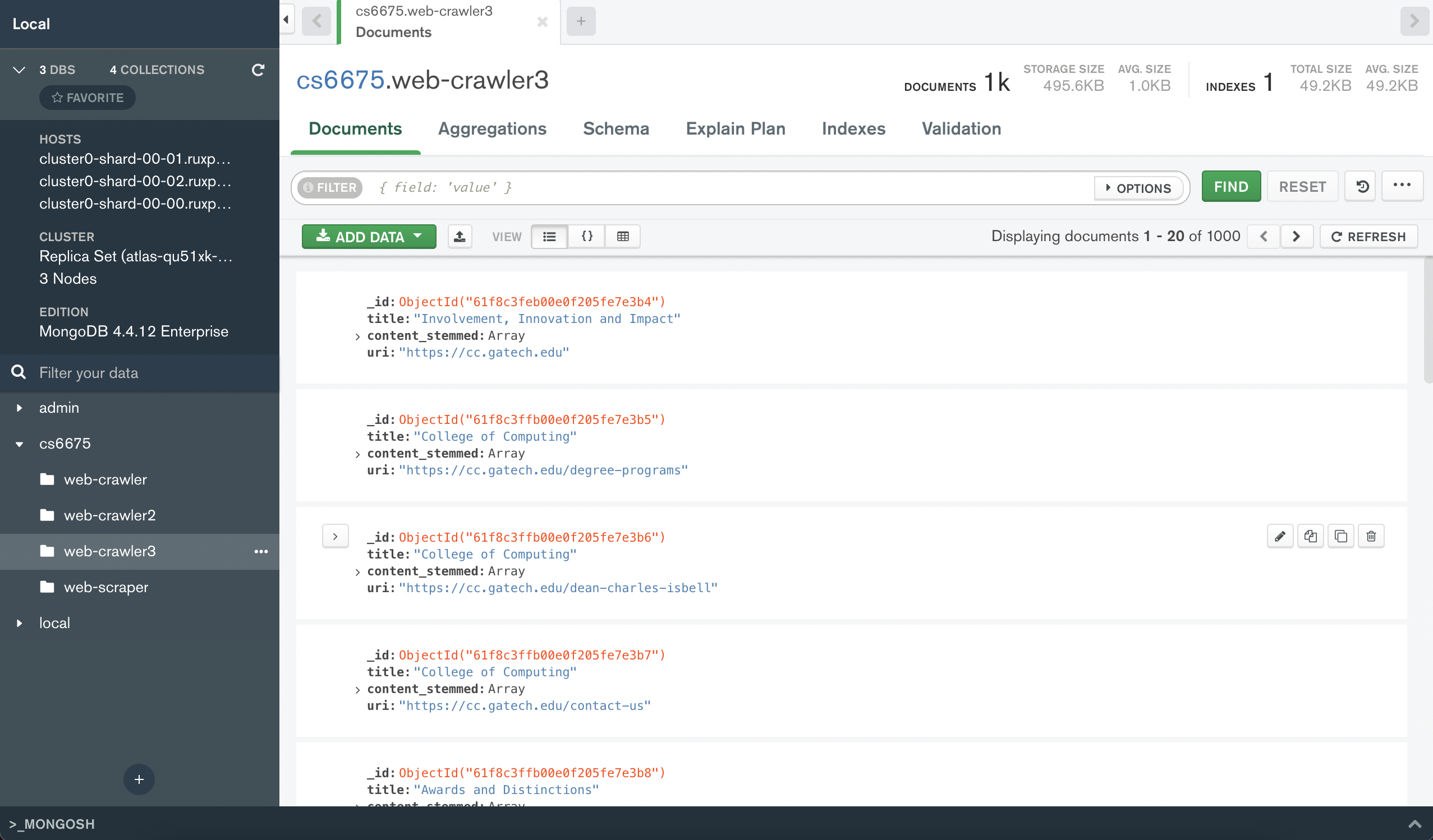
Results
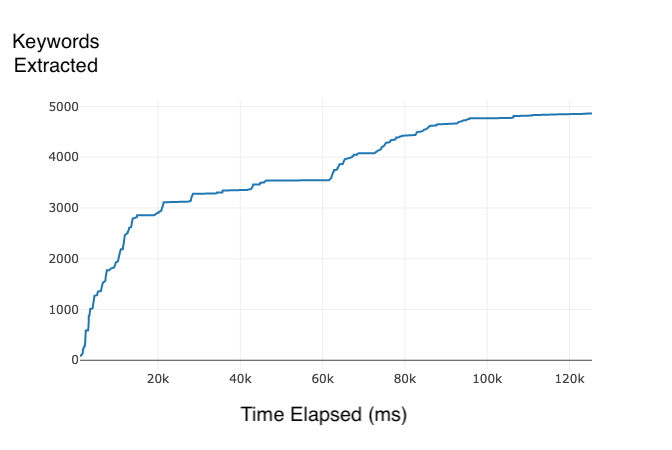
I crawled 1000 web pages in 2 minutes and 5 seconds, and made three plots with global metrics that were recording during the crawl.
- 4861 Keywords Extracted
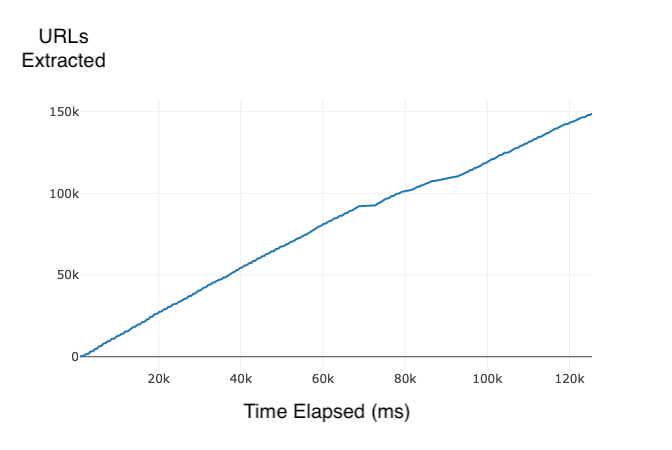
- 148834 Total URLs Extracted
- 73567 Crawlable URLs Extracted
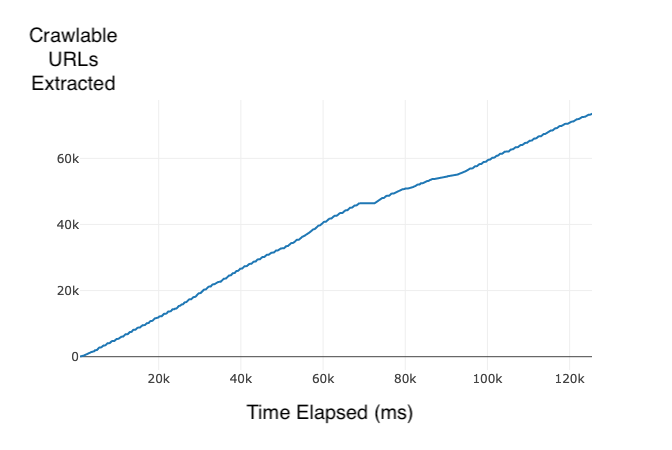
Estimations
Since we were able to crawl 1000 pages in 125 seconds, assuming we continue to crawl at an average of .125 seconds per page, we can estimate how long it would take to crawl the following numbers of pages:
- 10 million pages
- 1250000 seconds = 20833.33 minutes = 347.22 hours = 14.4 days
- 1 billion pages
- 125000000 seconds = 2083333.33 minutes = 34722.22 hours = 1446.75 days = 3.96 years
Lessons Learned
Overall, I had a lot of fun playing with Node outside of a React context, and enjoyed creating a web crawler basically from scratch. I learned how to effectively track performance of Node runtimes and how to plot with a matplotlib-like npm library nodeplotlib. The estimation for how long it would take to crawl 1 billion pages really opened my eyes as to how much computing power companies like Google must have in order to constantly crawl the entire internet and keep their records up-to-date.
References
https://github.com/NaturalNode/natural
https://github.com/bda-research/node-crawler
https://www.npmjs.com/package/nodeplotlib