CS6675 P2P Image Sharing
This post is the analysis for my second homework assignment of CS6675.
View the source code at My Github.
Overview
For this assignment, we were tasked to experiment and record metrics of a Peer to Peer File Sharing Network.
Idea
I decided to attempt to make my own P2P Image Sharing application with React using WebRTC.

At its core, WebRTC is a framework for real-time communications on the web, and allows browsers to communicate directly with each other using web sockets. This really sparked my interest, because in the past I have needed to share confidential documents with people over the web and always felt uneasy that my documents are living in a database somewhere. With WebRTC, we can share files directly with another browser avoiding any servers and ensuring a secure data transfer.

WebRTC can be pretty tedious to use on its own, so I decided to use a helper library PeerJS that deals with a lot of the annoying minutiae of WebRTC.
Design
The design of the application can be split into three parts: the frontend, middleware, and backend.
Frontend
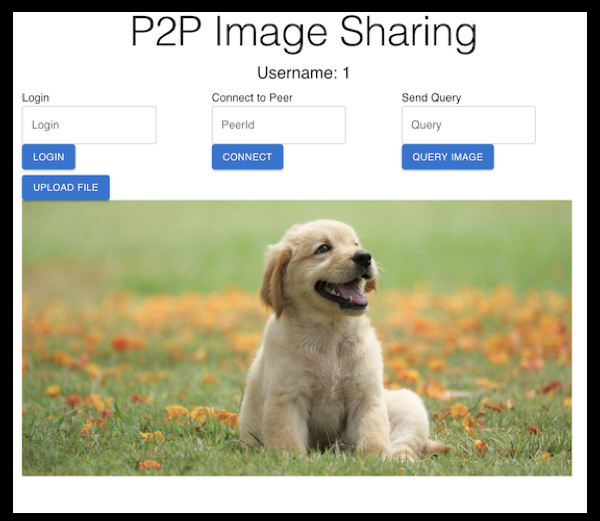
The frontend of the application is very simple. It allows you to “Login”, which essentially establishes you as a Peer on the network with an id being your username, and store an image on your client. Next, you can enter an id of another peer you want to connect to and establish a P2P connection with them. Once you have active connections, you may query the network with any keywords you would like to search for.
Middleware
PeerJS recommends to have a Peer Server that aids in creating the connections between peers. No data transfer occurs through the server, it simply only adds peers to the network and establishes connections.
Backend
When a client sends a query request, a BFS traversal occurs through your Peer Tree of the P2P Network Forest. In order for this functionality to work, I created a communication protocol for the P2P communication. Essentially, if a Peer receives data with type ‘query’, it will check its local images to see if it has one that satisfies the query, if it does, it will establish a direct connection with the Peer who started the query (the ‘asker’) and send the asker the image with data type ‘FileFound’. If it does not contain the image, it will continue passing the query to its direct neighbors. In addition, to prevent the search of duplicate nodes, every query has a unique id, and every Peer keeps a ledger of what queries it has previously served. If a Peer receives a query request it has already served, it will simply ignore it.
Example
Check out this video example!
Results
I decided to test my network by recording how long it takes for the asker to receive an image result with a variety of 5-Peer P2P network configurations. In some configurations, I have images saved at two of the nodes in the graph, and hypothesized that the closer nodes would send data to the asker first.
Here is an example of the console output of the application.
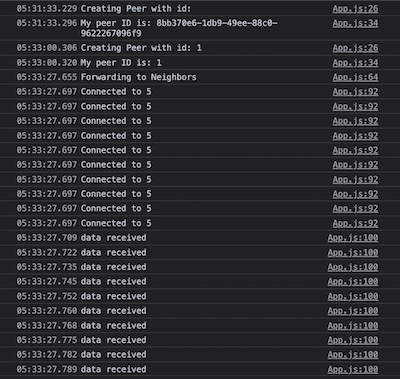
4-Hop Query
In this query, the asker node is Peer 1, and the image was stored in Peer 5.
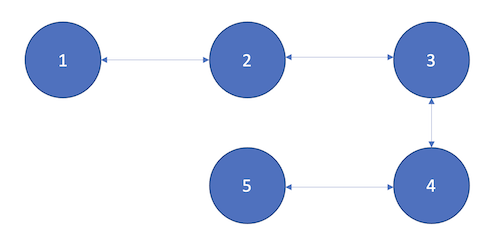
The image was 4 hops away and took 70ms for the asker to receive it.
3-Hop vs 2-Hop
In this query, the asker node is Peer 1, and the image was stored in Peers 4 and 5.
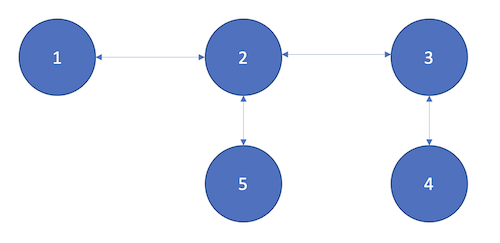
The images were 2 and 3 hops away. It took 61ms for the 2 hop image and 250ms for the 3 hop image.
3-Hop vs 1-Hop
In this query, the asker node is Peer 1, and the image was stored in Peers 4 and 5.
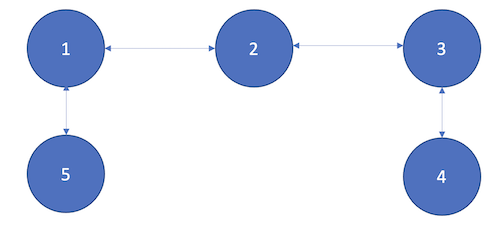
The images were 1 and 3 hops away. It took 32ms for the 1 hop image and 184ms for the 3 hop image.
2-Hop vs 1-Hop
In this query, the asker node is Peer 1, and the image was stored in Peers 4 and 5.
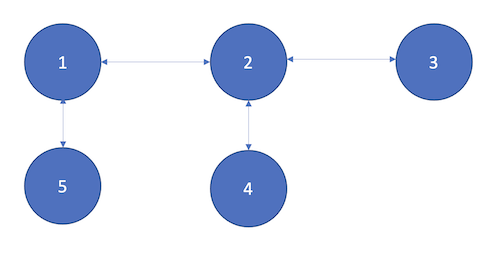
The images were 1 and 2 hops away. It took 47ms for the 1 hop image and 198ms for the 2 hop image.
Overall
Like I predicted, the closer images were always found first due to the BFS traversal.
For the scenarios with two downloaded images, the difference between the two downloads was big. I think this was due to JavaScript being single threaded, so while the first image was being downloaded the second image was waiting to be downloaded.
For the download times that were not delayed, we averaged 26.25ms per hop. If this trend were to continue for 1000 hops, our download time is estimated to take 26.25 seconds. For one million hops, it would take 26250 seconds = 7.3 hours.
Design Tradeoffs
This P2P network application would not be good to use in large-scale scenarios for sensitive data. Once you are on the network, any node on the network can connect to you if they know your id and start sending you data. As we saw in the results, downloading two images at once can severely impact performance, so DDoS-like attacks are a very real possibility if your id is known.
In addition, you do not necessarily know what nodes have access to your information. This is because Peers you connect to have other peers connected to them, which you are indirectly connected to.
While these are privary/security concerns, the network is extremely self-scalable and does not rely on any dedicated servers other than to create connections.
Future Work
If I were to continue working on this project, I would first create functionality so that you can make private files that can only be accessed by specific peers. I would also add some sort of connection protocol if a Peer disconnects from the network to prevent splitting trees on the removal of a node.
Lessons Learned
This application has not been tested with images other than png and jpeg, and is not fault tolerant. It is only meant to be a Proof of Concept for the possibilities of P2P file sharing using PeerJS.
Aside from those facts, I definitely learned a lot from this project in terms of interacting with web sockets in JavaScript. I have done some sockets programming with Python in the past, but the behavior is different because in Python you can multithread for your outgoing and incoming data, while JavaScript is single-threaded, so you rely more on event listeners.
References
https://webrtc.org/
https://peerjs.com/